Our assignment for this week was to work with external data: loading JSON files with data sets and using them to visualize the information within. Getting familiar with using APIs lets you pull JSON files from popular websites and web services.
The example videos from Shiffman seemed to make sense, but it wasn’t necessarily smooth following along. It seems like the New York Times API documentation and services work in a slightly different way than when he had used it. This meant that certain code didn’t quite work.
Instead of providing a solid example URL, you are given the following code:
var url = “https://api.nytimes.com/svc/search/v2/articlesearch.json”;
url += ‘?’ + $.param({
‘api-key’: “a74472e8eca541b2b2577c690b887abe”,
‘begin_date’: “20161025”,
‘end_date’: “20161025”
});
$.ajax({
url: url,
method: ‘GET’,
}).done(function(result) {
console.log(result);
}).fail(function(err) {
throw err;
});
Using the $ didn’t seem to play well nice with p5, so I needed to piece the puzzle together and write the proper URL “by hand” to see if I could get a proper response JSON file. Fun fact, it seems like APIs that are mis-written in certain ways don’t just refuse to work. When I was looking for article headlines by date, my malformed query would respond with today’s headlines. Of course, I used today’s date as my initial test to see if I could get information from the API. So it wasn’t until later when I was playing around with different day requests that I noticed nothing I put in was working.
I was a little distracted by that because I had spent a good chunk of time trying to figure out the spacing of my project. And because of all the GIFs. What GIFs, you say?
https://alpha.editor.p5js.org/projects/rykND901x
My idea was to use not one, but two APIs. The user can enter a date to get a headline from the New York Times on that day, and then each word is run through the Giphy API. Each search returns an image that puts a GIF on the DOM, creating a chain of GIFs that are “translated” from English. Perhaps this technique can help revitalize the print media industry.
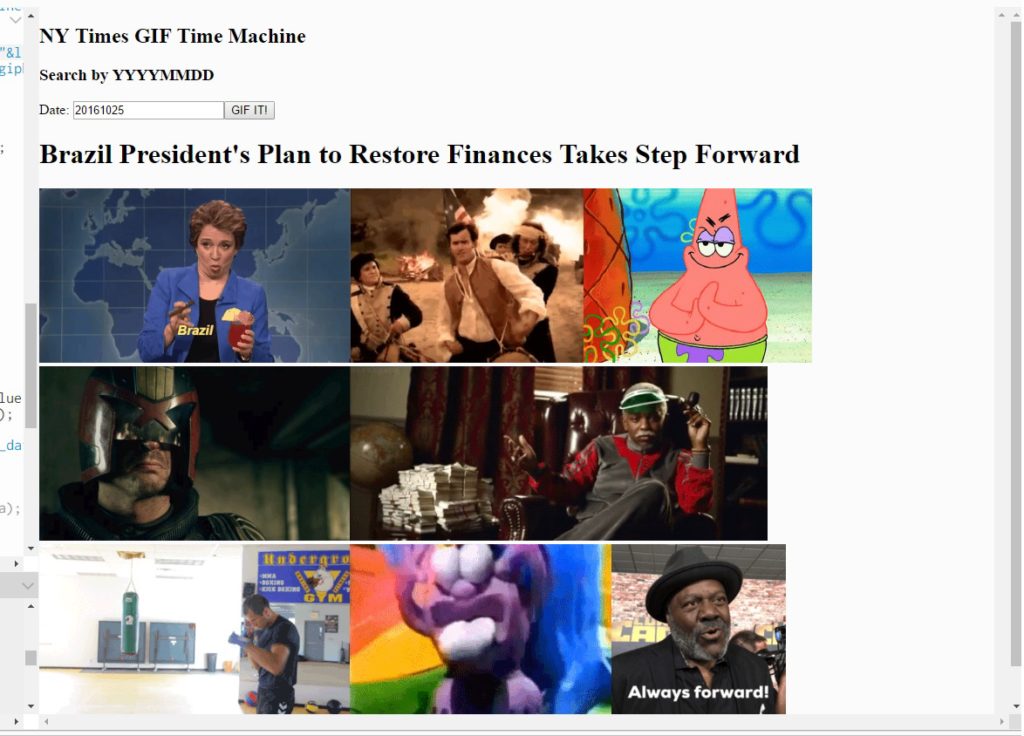
The main issue was the timing of the different API calls. There is still a bug where the GIFs aren’t necessarily placed in proper order. Clicking the button again can remedy this, and the bug doesn’t always show up. It seems that simply the time required to start a new API call for each word and load the GIF messes with the sequential nature of the loading. I spent lots and lots of time trying to figure out how to avoid this and make sure that the images would always be in the right order. Still haven’t managed to figure it out, but in general the proof of concept is functional enough and fun to play around with.